

三分钟搞懂数据编织:破解金融数据管理难题!
1.数据编织(Data Fabric)是什么?
数据编织是一种智能数据架构,就像是一张“网”,将分散在数据库、数据湖、文档中的不同来源、不同格式的数据动态连接,让企业能够更加高效地访问、管理和分析这些数据。
2.金融行业为什么急需数据编织?
面对大模型技术的发展,数据作为重要支撑元素,急需解决如下诸多挑战:
数据孤岛:历史库、实时库、指标库等数据分散,跨平台查询效率低;
血缘分析难:数据从哪儿来到哪儿去?数据是否合规?数据链路复杂,手动追踪维护耗时耗力;
智能化不足:传统的数据集成方式依赖ETL(提取、转化、加载),这不仅工作量大,而且数据处理效率低,限制了业务决策的敏捷性。
3.可利邦数据编织方案的核心能力
数据虚拟化:打破数据孤岛
无缝连接异构数据源,屏蔽底层技术差异,实时响应业务变化,无需预建ETL流程。
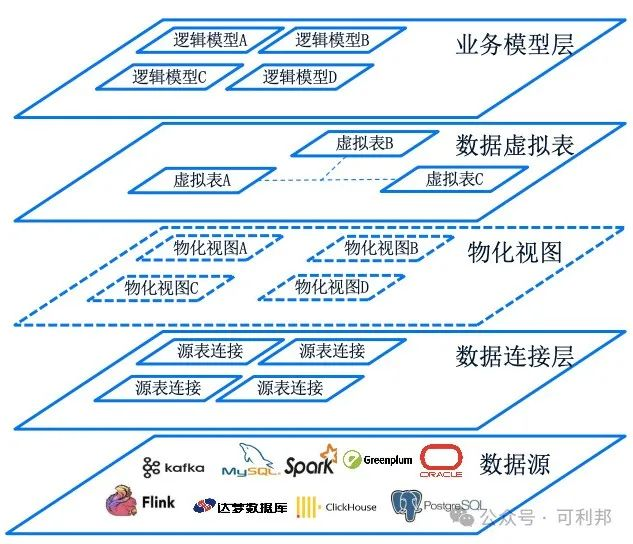
将“不可用”数据,迅速转化为“可用”数据
自动化血缘分析:让数据链路透明化
算法实时解析数据的流动路径,并自动构建知识图谱,帮助金融机构清晰地了解数据全生命周期。
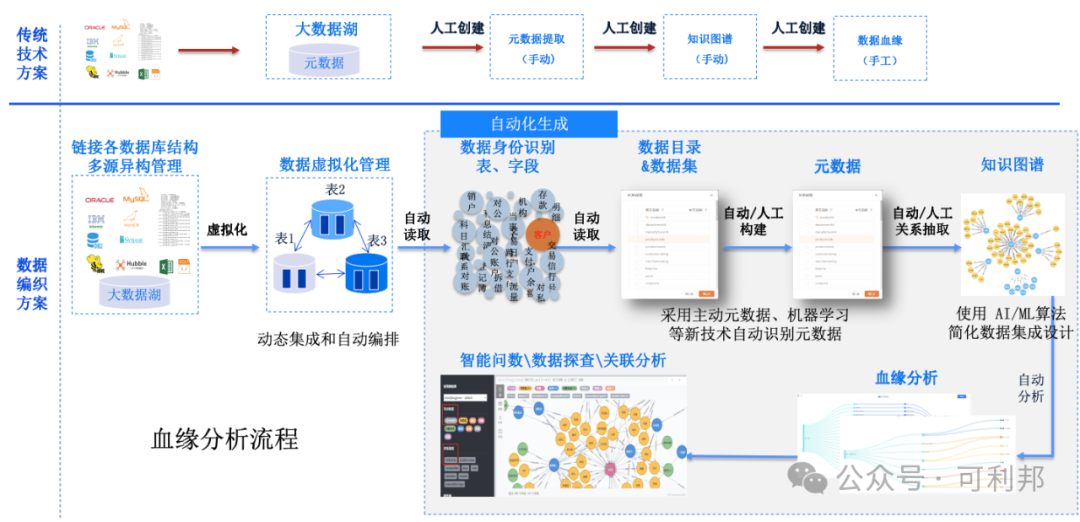
数据编织方案流程
对话式数据分析(智能问数)
基于大模型实现数据交互,业务人员输入“查询过去一周单笔交易超过50万的客户名单”,系统自动关联交易库、风控标签库等并生成图表;
30+可视化组件:包括柱图、条形图、雷达图、散点图等。
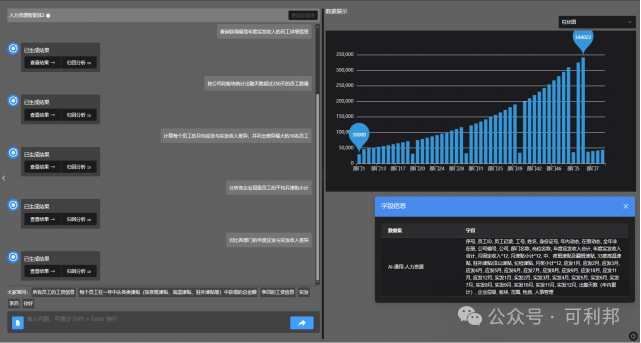
交互案例
4.金融行业落地场景
场景1:反欺诈
整合来自多个数据源的数据,如交易记录、客户行为、黑名单库等,进行实时分析和监控,拦截可疑交易。
场景2:智能投资与资产管理
数据编织能够将海量的市场数据、客户数据和经济指标实时汇聚,通过智能分析为投资经理提供决策支持。
场景3:合规性和监管
自动映射监管字段,血缘分析确保数据的透明性和可追溯性,帮助金融机构更好地应对监管要求和政策变化。
 京ICP备2021033509号
京ICP备2021033509号